Selecting between Queue, Topic and Event Hub:

Usage:
Queue:
The scenario for queue is almost clear. Each message will be receive only by 1 receiver.
Of course it is possible to have multiple senders and multiple receivers, but the key point is that each message will receive only to one of those receivers.

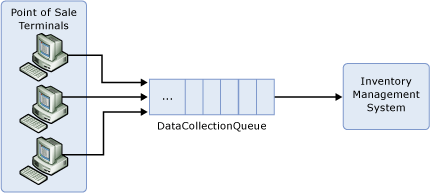
A simple example of using queues is POS (point of sale) systems. POS terminals produce some data with different load/times and the inventory management system has to process all of them. The inventory system and the Terminals are loosely coupled there might be different softwares in each terminal, but there is only 1 receiver on the other end.
Topic-subscription:
This type of queue will be used when a single message has to be received by multiple receivers. It is also possible to differentiate between receivers so a group of receivers will only receive special types of messages.
The same as queues, there can be multiple instances of sender/receivers (multiple receiver per subscription) is available, but when a receiver reads data from 1 subscription, the others cannot read it again from the same subscription.
A simple example for this scenario is logging/Search. You want to have an instance of your data to use in a logging (search) system, but there has to be no relation between your realtime system with the logging system rationally.

The second scenario is also possible when you want to divide your messages into different lines. Like when you want to create a priority queue, or when a set of producers produce data for different systems.
A simple example for this would be when you create data in a way and process them in different manners. For instance if there is an ordering system registers orders for different companies, then each company only needs to know about its orders.
Event-Hub:
Event Hub is simply a big stream of data. In a way, Event hub is the answer for the same issues that we addressed in the Topics. There are multiple consumers for each message, but the big difference is that Event-hub has been implemented for maximizing the throughput.
Each Topic in event hub will multiple partitions (normally between 4 to 16) and 1 instance of the client will read from each partition. If any of the clients goes down or there are less clients that the partitions, clients will compete against each other to access to more partitions.

A simple scenario for this solution is logging players actions in a popular game.
How they Access data
Queue:
There is only 1 line of messages. Clients wait for a message and when a new message received, only one of them will process it.
Topic-subscription:
There is only multiple lines of subscriptions. Clients of a subscription wait for data and the same scenario as queues happens here. It is important to note that there is no relation between data in different subscriptions.
Event-Hub:
Clients are responsible for the data that they read. Meaning that it is possible for different clients to read a message multiple time. Messages would not remove from system until a reasonable time (some days), or depending on size of data.
Each client will ask the hub for data after special message (check point) so it is very possible to see some messages has been read multiple time when a client restarts.
There is a concept of Consumer Groups which is almost the same as subscription in the topic base service bus.
How to manage failure
Topic-subscription:
There is 2 ways of receiving a message:
1- PeekLock (default)
Data will be read by the client and it will be locked for some time. When the client finished its work, it simply tells to the broker that and the broker will remove the item from queue.
If an error happens in the process client can abandon the message, therefore another client would read the same message later on in case that the error was temporary.
Also, if the client crashes in the middle of the process, the lock will be time outed and the message will be readable for another client.
2-ReceiveAndDelete
The broker doesn't care about the probable errors. It simply say the message will be read 1 times max!
Event-Hub:
Messages will be in the hub for a long time, so we can be sure that data will be read by clients at least 1 time.
Each client will set a check point after a portion of time (or any rule that the clients decides) and if it restarts, it will continue reading from that checkpoint again. So the client has to take care of duplicates it self.
Installation Environment
Queue and Topic-subscription are available on both Microsoft Azure (cloud) and on premise but Event-Hub is only available on the Azure.
Read More
Azure Event Hubs overview